
Learning, storing, and retrieving information – from random scribbling to high-end data storage has always been an involuntary practice in our day-to-day life. Considering the time from the pre-historic era, where our ancestors had engraved in cave walls, to the present eon of big data and information explosion, it is estimated that about 1.7 megabytes of data are created per second per person globally, assuming a world population of 7.8 billion. With such a boom, our present technology of magnetic and optical data storage systems cannot hold on for more than a century, and then we will be having a severe data-storage problem. One of the fascinating alternatives to this problem came up with the idea of Soviet physicist Mikhail Samoilovich Neiman, who suggested the possibility of creating storage devices based on artificial DNA molecules. This idea sounds much exciting, knowing that this technique was time-tested by our nature. Just think about the information storage and replication that have occurred in our genetic code since the beginning of life on Earth, the process by which we transmit our heredity (inheritance).
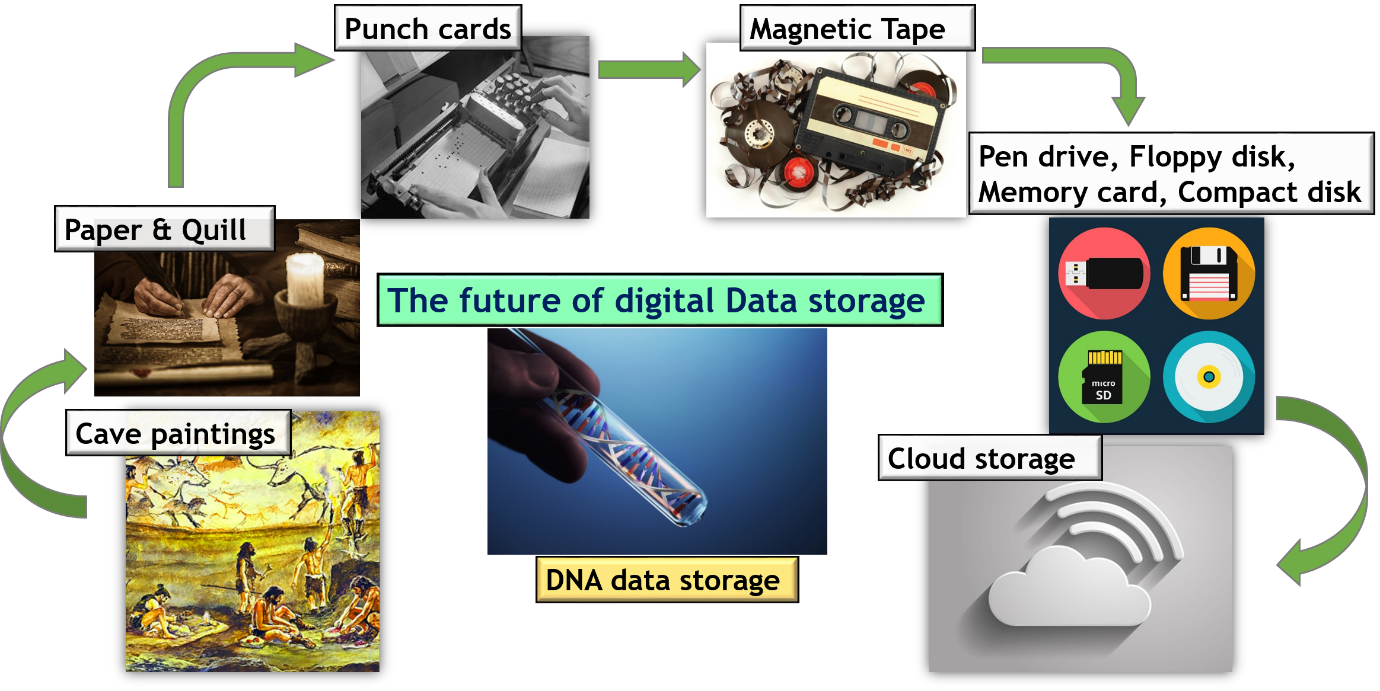
Figure 1: The evolution of data storage devices
The working mechanism of this high-density data storage system is similar to the way the genetic information is encoded in our cells: As opposed to the binary coding system (0 and 1), the building blocks of DNA consists of four bases, Adenine (A), Thymine (T), Cytosine (C), and Guanine (G). This variation itself means that DNA can store twice as much data as a binary program (Nat. Mater., 15, 366–370 (2016)). For example, “Hello” could be coded into the chemical string TCAACATGATGAGTA, which is mapped using a specific algorithm. This long digital sequence of DNA is synthesized chemically and is stored in the form of a liquid drop in deep freeze where it can last for 100 years or can even be sent to external storage systems, which protect it for more than a thousand years. In its early stage, all these processes were done manually and hence not error-free.
Recently, with the help of the tech-giant Microsoft, researchers were able to demonstrate an automated system for the entire DNA coding-decoding process, making this technology a grand slam (https://www.microsoft.com/en-us/research/project/dna-storage/).
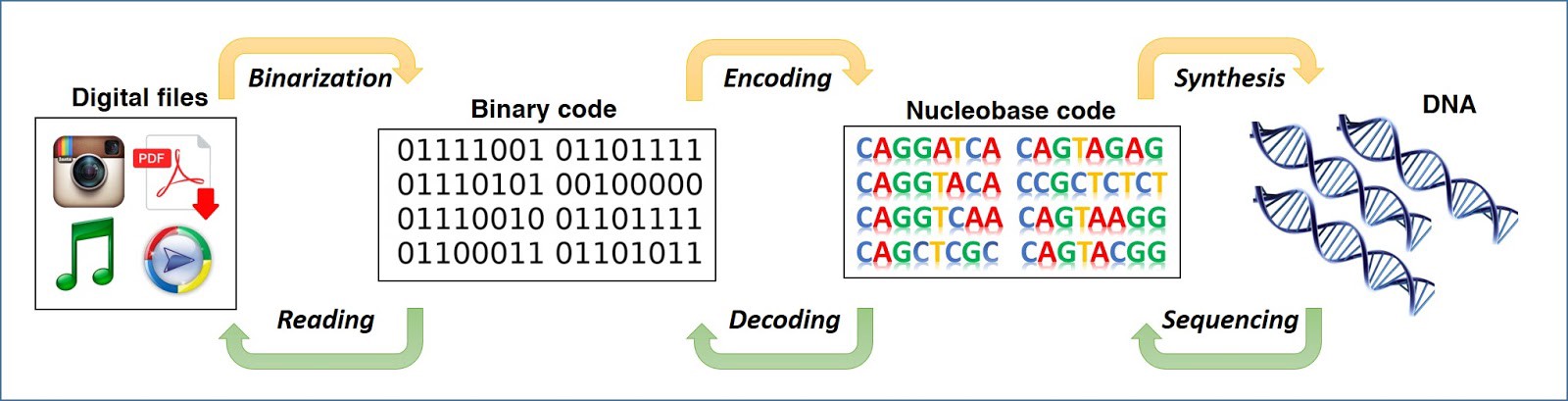
Figure 2: The mechanism of data storage in DNA
Even though the storage capacity of this budding technology is six orders of magnitude denser than the densest media available today, one has to sequence it entirely for retrieving a finite part of the information and the entire process is time-consuming and expensive. But, compared with the conventional data storage devices, whose information can get corrupted permanently even when stored under ideal conditions, DNA data storage has an extreme shelf life. The average half-life of a strand of DNA is about 512 years and the fact that researchers were able to recover the complete genome sequence of a fossil horse that lived more than 500,000 years ago itself proves the durability of this technology.
The potential for huge memory storage (about 1018 bytes of information in one gram of DNA; https://apps.dtic.mil/sti/pdfs/ADA431849.pdf ) and massive parallel production capability (up to 1020 operations s-1; Nanotech., 17, R27–R39 (2006)) makes it one of the most discussed topic. Advanced research into this nature’s oldest data storage system offers huge promise for an error-free, viable, and incredibly stable storage device providing wide practicality in the future.
Ms. Gayathri R. Pisharody
Senior Research Fellow
Group of Dr D S Shankar Rao.
CeNS, Bengaluru